
声明:本篇文章纯为原创,未经过AI人工智能合成。如有雷同纯属巧合。
Attribution-NonCommercial-ShareAlike 4.0 International
This license requires that reusers give credit to the creator. It allows reusers to distribute, remix, adapt, and build upon the material in any medium or format, for noncommercial purposes only. If others modify or adapt the material, they must license the modified material under identical terms.
理想模型
理想的问答系统是用户使用系统能够精准的获取需要的答案,并且通过自然的问答来实现知识的积累。并且在问答过后还可以给出几个相关问题建议吸引用户继续问答的兴趣以便更好的了解相关知识,在人工智能问答飞速发展的时代,越来越多人希望问答系统能够自然连续的回答并且答案让人满足和信服。
理想模型中机器人需要通过匹配或拆分用户输入的语句并进行语义上的推测与统计,能精准掌握用户问题的意思与疑问点,并根据这些疑问点匹配最合适的答案并将这些答案进行语义组装成一个通顺完整的句子
这种自然的问答系统不仅需要庞大的数据做支撑还需要特殊的人工智能神经网络加持甚至需要AI芯片硬件。这种理想模型的实现是非常困难的,作为Python的初学者我们只好对现实做出极大的妥协
妥协(模型定义)
首先对于理想模型,我们既没有AI芯片硬件同时也没有庞大的数据同时也不会人工智能神经网络的构建所以智能对理想模型做出妥协
大体上使用预设问答对
作为Python初学者我们只能做出最简单的依靠匹配进行的一问一答的类FAQ的问答系统,通过预先建立的问答对进行对话。也许这样会太过生硬,但是当建立的问答对足够多的话还是可以解决大部分问题的
何为FAQ系统
FAQ是英文Frequently Asked Questions的缩写,通俗地叫做“ 常见问题解答 ”
FAQ是网络上提供在线帮助的主要手段,通过事先组织好一些可能的常问问答对
逻辑上使用字符匹配
包含匹配
用户的问题中包含着预设的问题对的问题(预设问题长度<用户问题长度,预设问题题目是用户问题题目的子集)。比如用户提问:“为什么1+1=2”,而预设的问题对中含有“1+1=2”的问题,就会根据所占用的长度比例(预设问题题目长度占用户问题题目的字符串长度比例)进行匹配。
预测匹配
用户问题长度小于预设问题长度,并且用户问题字符是预设问题字符的子集。比如用户问饱和食盐水和碳酸钠,在包含匹配没有结果的情况下使用预测匹配,匹配到“求高中饱和食盐水和碳酸钠,碳酸氢钠溶液各有什么作用!”为问题的预设问题对。同时也根据所占用的长度比例进行匹配,比如除匹配到上述预设问题对外,还匹配到了求饱和食盐水和碳酸钠是什么这个预设问题对,因为这个用户问饱和食盐水和碳酸钠占求饱和食盐水和碳酸钠是什么这个预设问题对的比例大于“求高中饱和食盐水和碳酸钠,碳酸氢钠溶液各有什么作用!”为问题的预设问题对,所以返回求饱和食盐水和碳酸钠是什么的答案。
概率匹配
这里定义的概率匹配是通过拆分用户的分词与问答中列表分词进行概率上的匹配,比如将问题“牛和羊的具体的区别是什么?”进行分词,并与文件中的问答对数据进行拆分,发现“牛”、“羊”、“区别”等关键词占比占预设“牛和羊的区别”问题的比例较大,返回预设“牛和羊的区别”问题的答案。这种操作能够更容易答上用户的问题但是容易出现答非所问的现象,通过调整概率能够减轻这一问题带来的影响。
1.实现思路
1.1.服务端和客户端
我们应该建立两个独立的功能,一个用于向某个端口发送数据流(客户端)client_socket.send(message.encode('utf-8'))。另一个则是监听这个端口(服务端)并将监听到的数据流转为str型进行匹配处理,处理完后将匹配结果(答案)以发送数据流的形式返回客户端,客户端再将收到的数据流解码后打印在显示屏上
1.2.问题匹配
1.2.1 包含匹配
包含匹配是一个在服务端处理监听到客户端发来的数据流编码后字符串的重要机制之一,用于判断预设问题题目是否为用户问题题目的子集。主要思路是将传入的字符作为words与预设题目line使用第三方判断库re进行re.search(line, words)判断预设题目是否在传入字符中,并将多个匹配的预设题目line保存到列表中,而后根据列表中的预设题目line长度占用户问题题目words长度比例,所占比例大的预设题目line对应的答案。(一般来说,line是words的子集,words是用户字符串长度不变情况下,line越大,所占比例越大),如果line不是words的子字符串,则进行预测匹配。
1.2.2 预测匹配
与包含匹配一样,主要思路是将传入的字符作为words与预设题目line使用第三方判断库re进行判断,不过并不是使用re.search(line, words)re.search(words, line),将words作为line的子字符串。此时,words是用户字符串长度不变情况下,line越小,所占比例越大,所以在列表中寻找匹配到的最短问题作为最小关键字(min_keyword),并使用min_keyword在预设问题对中匹配。如果words不是line的子字符串,则进行预测匹配。
1.2.3 概率匹配
与上面两个匹配方法不一样,概率匹配需要将传入的字符words与预设题目line[i](每一组)分别进行分词(使用jieba第三方库),并将每一组分词进行匹配,将匹配到的比例(分词匹配概率)在每一组进行比对,取比例(概率)最高的line[]作为关键字在预设问题对中进行匹配。为了防止答非所问,我们还需要设定与一个最低概率,如果比例(概率)最高的line[]的比例(概率)小于预设的比例(概率)那么则输出“对不起,我不明白您的意思”。
1.3 预设问题创建与读取
通过预设一个具有问题对的配置文件ini,格式如下
1 | 问题1=答案1 |
通过读取每一行并按照line.split('=')[0]: line.split('=')[1]的格式(Question : Answer)进行处理并使用text[Question]获得Answer
由于配置文件ini需要放在指定地点过于麻烦,可以将ini文件放在自己服务器中的’https://file.i-nmb.cn/python/dict.ini'并通过requests第三方库获取
2.具体实现
2.1 服务端代码
2.1.1服务端初始代码
首先初始化服务器
1 | server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) |
监听本地端口127.0.0.1:4040,并且将监听数设置为5
之后做出以下尝试
1 | while True: |
尝试获取端口号和地址信息后使用dealclient函数并传递sock, addr,如果在获取客户端信息获取错误时退出循环并关闭服务器否则已知监听4040端口并滞留在server.accept()等待新连接
由于本服务端需要联网获取自己服务器上的ini,先下载ini文件
1 | url = 'https://file.i-nmb.cn/python/dict.ini' |
下载ini配置文件到本地后,服务端使用
1 | with open('dict.ini', 'r', encoding='utf-8') as file: |
对ini文件进行解析
之后对代码进行可视化(添加print调试信息)的优化
初始服务端代码如下
1 | # 从文件中加载字典内容到变量中 |

2.1.2服务端接收和处理信息
接收信息
处理函数dealclient中使用recv获取来着4040端口的数据,这里使用except socket.error as e抛出错误,避免服务端的控制台爆红。同时我们需要控制服务端退出字样,即客户端输入exit服务端对其断开连接,加上调试信息后如下所示:
1 | def dealclient(sock, addr): |
处理信息(各类匹配实现方式)
处理信息分为两步,一步是匹配问题,一步是发送答案。
在匹配问题方面,首先采用包含匹配,根据前文思路,我们需要先对data进行编码(使用utf-8编码成字符串)words = data.decode('utf-8'),之后采用列表str_list用来存储,使用for循环对dicts进行遍历
前文
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
如果匹配到(`result = re.search(line, words)`)则将line放入存储列表`str_list`,若`str_list`中拥有元素则判断最大关键词(最长的line),并将最大关键词作为问题匹配答案,其他关键词还在存储列表`str_list`中,将匹配的答案输出`sock.send(bytes("机器人回答:", encoding="utf-8") + dicts[max_keyword].encode('utf-8'))`如果剩余列表不空则输出<u>猜你还想问</u>之后continue循环重头
具体代码如下

若`len(str_list) == 0`则不执行以上代码,并向下继续执行**预测匹配**。仅需将~~`result2 = re.search(line, words)`~~改为`result2 = re.search(words, line)`并匹配最小关键词即可
<img src="https://img1.i-nmb.cn/img/image-20231109232931120.png" alt="更改" style="zoom:70%;" />
<img src="https://img1.i-nmb.cn/img/image-20231109232948467.png" alt="更改" style="zoom:70%;" />
同样的若`len(str_list) == 0`则不执行以上代码,并向下继续执行**概率匹配**。
概率匹配需要jieba的支持使用`pip install jieba`进行安装,并使用`jieba.cut_for_search(words)`进行分词发现生成的类型为`generator`虽然经过` word_list= [word for word in jieba.cut(text)]`能够转为列表,但是通过`jieba.lcut()`能够直接生成列表型

通过for循环使`用户问题分词列表words_participle_list`与`预设问题分词列表line_participle_list`进行遍历,使用标志`max_number`和`max_number_key`
来存放最大匹配次数和最大匹配问题。
```python
words_participle_list = jieba.lcut(words, cut_all=True)
print("[调试]输入问题分词为:" + '|'.join(words_participle_list) + "\n列表类型为")
print(type(words_participle_list))
max_number = 0
max_number_key = ""
for line in dicts:
number_of_matches = 0
line_participle_list = jieba.lcut(line, cut_all=True)
for words_participle in words_participle_list:
for line_participle in line_participle_list:
print("【调试】问题分词:“" + words_participle + "”与预设分词:“" + line_participle + "”对比")
if words_participle == line_participle:
number_of_matches = number_of_matches + 1
if number_of_matches > max_number:
max_number = number_of_matches
max_number_key = line
print("【调试】max_number为:" + str(max_number))
print("【调试】最大概率匹配问题为:" + line)
此外还需要对最大匹配词数与预设问题进行占比分析,查看最大匹配词数命中预设问题的分词的概率
1 | probability = max_number / len(line_participle_list) |
此时遇到一个问题,到底为最大匹配次数优先还是最大匹配概率优先。详细问题请参见后文的**“不足分析”**
这里使用最大匹配次数与最大概率双优先,这样的好处是匹配到的预设问题与用户问题的匹配程度高,但门槛高,容易匹配不到已有问题,两级分化严重
为了避免机器人答非所问,我们需要设置一个匹配占比(概率值)门槛,若超过这一门槛则输出预设答案,否则加入“猜你想问”模块,避免答非所问的情况。
在改进的代码中我们预设初值并使用if number_of_matches > max_number and probability >= max_probability:来筛选合适的答案
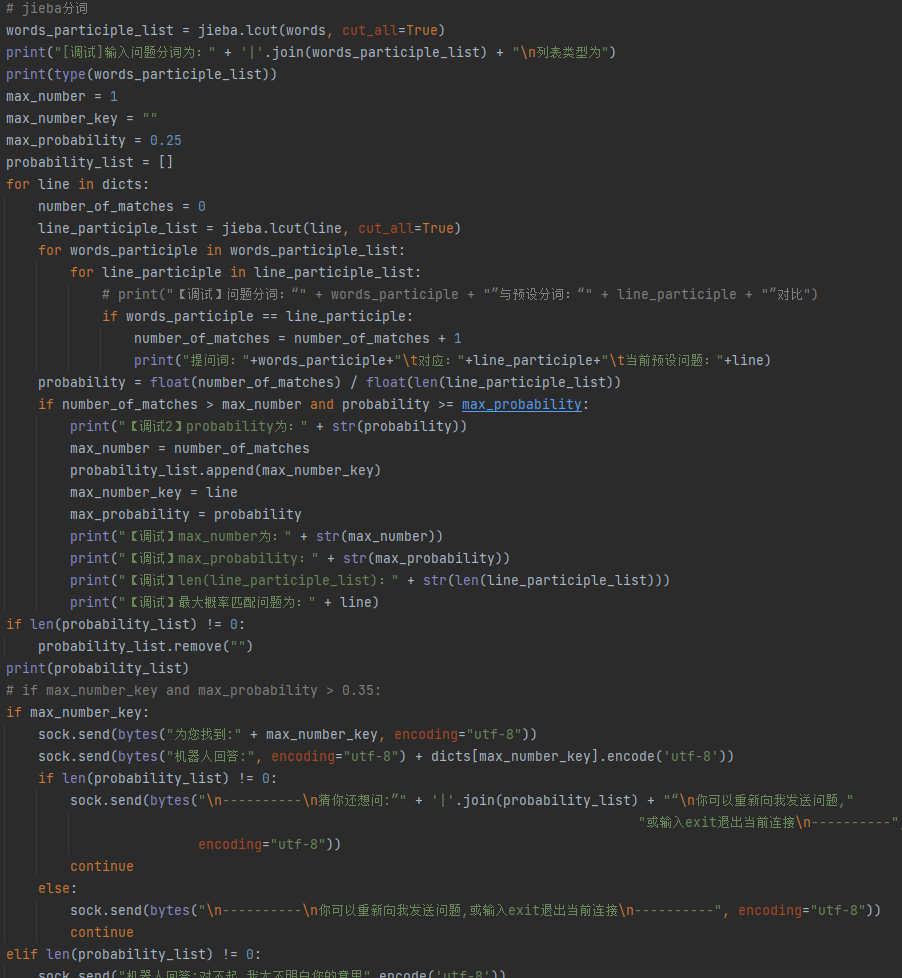
如果以上还是匹配不到的话则向客户端输出
1 | else: |
至此,服务端代码结束,具体代码请看附件。
2.2客户端代码
分析:客户端中只需要建立连接后向服务端发送数据流和接收服务端数据流即可
使用client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)初始化客户端,并用.connect()建立连接后使用.send(message)发送数据,使用.recv()接收数据,并使用print打印在屏幕即可。
为了增加用户的可视化性,我使用print()进行页面的交互优化。
以下代码使用socket进行与服务端的连接若连接失败则抛出错误详情防止爆红
1 | def client(): |
之后进入循环,并检测用户输入的数据是否合法(从安全角度上来看还需要在服务端进行检测)。如果输入字符为空则重新输入否则使用client_socket.send(message.encode('utf-8'))向服务端发送数据流,之后使用data = client_socket.recv(1024)接收来自服务端的数据流,并通过print(data.decode('utf-8'))打印在屏幕上。
前文在服务端设置了输入exit关闭连接,这里判断是否为exit,若为exit则发送后跳出循环、关闭连接
代码如下:
1 | while True: |
使用main函数启动代码
1 | if __name__ == "__main__": |
至此,客户端代码结束,具体代码请看附件。
3.结果展示
服务端展示
仅展示服务端可视化页面,具体回复与问题处理结果见“客户端展示”
当启动服务端时,将初始化配置文件ini、监听端口号以及等待服务端连接
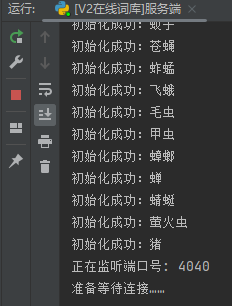
当有服务端连接时,显示详细信息

对于多客户端连接:
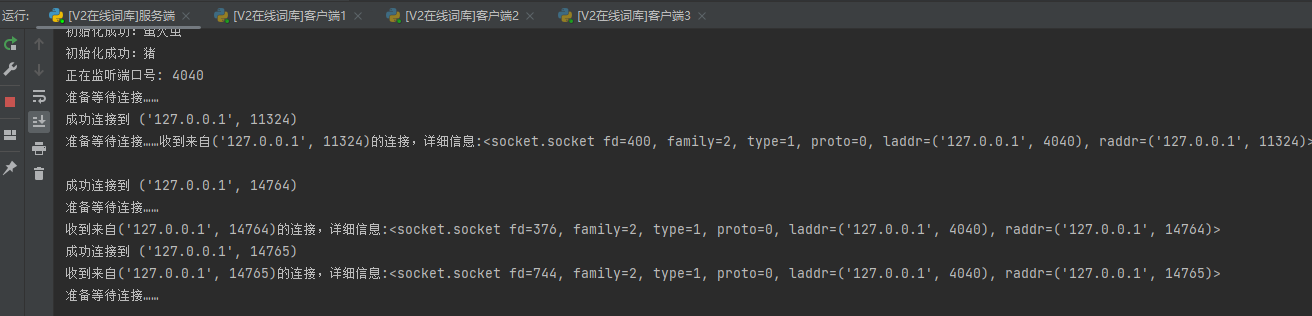
监听到不同客户端的ip和端口
当服务端退出后,关闭与客户端的连接

客户端展示
启动后根据上述代码判断 client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)和client_socket.connect(('127.0.0.1', 4040))显示是否成功连接到服务器。
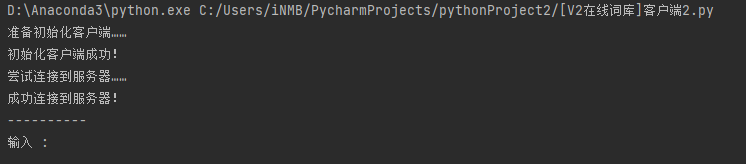
当我们发送问题后接收到服务器的回复并展示,如果有相似问题则输入到“猜你想问”中

之后还可以再次输入,若输入的问题不在预设问题中存在,则输出不明白你的意思

当输入exit后退出客户端进程
具体效果还需要自行运行体验
4.不足分析以及部分更正
如前言所述,若此方法对配置文件的预设问题过于粗糙不精细,则容易出现答非所问的现象并不能做到还原真实聊天场景。
本客户端没有可视化界面(UI),对用户操作不太有好。
此外,在使用客户端recv等待回复的时候若服务端的sock.send()数目与client_socket.recv()不匹配(一般是client_socket.recv过多)则会出现客户端无限时长等待的现象。需要细心匹配.send()与.recv()数量
预测匹配以及包含匹配中需要将词语占比做出限制,不然将出现下图错误

在概率匹配中没有很好的处理单字符的100%概率匹配的关系,比如提问“猫在黑暗中看见老鼠”若在配置文件中有预设问题题目“猫”和“猫在黑暗中为啥也能看见老鼠”,若“猫”问题在前则它以100%的匹配率阻止“猫在黑暗中为啥也能看见老鼠”这个多关键词的问题进入候选,反之,则以多关键字阻止高匹配率进行候选。解决这一问题还需要重新整理判断架构。目前由于时间紧迫,重构判断架构暂时被搁置,为了问题得以解决我们将预设词多的题目向前排序,舍本逐末的避免答非所问的现象。
在匹配过程中需要大量的数据由于收集的数据十分有限,需要更多的长句作为频率匹配的基础才能更加完整的表达。
特别鸣谢
感谢马伟老师的辅导与帮助,以及课上的谆谆教诲和精心指导。
感谢一位不愿透露姓名的同学对于本系统提供的系统结构框架。
感谢王同学提供的多线程和TCP服务结合的建议。
技术参考链接
jieba.cut与jieba.lcut的区别:https://blog.csdn.net/blackieliu/article/details/121573972
jieba分词使用方法:https://blog.csdn.net/laobai1015/article/details/80420016
今天我们聊聊“.ini”文件的打开方式和遇到的问题:https://zhuanlan.zhihu.com/p/635906339
网络编程Socket之TCP之close/shutdown详解:https://zhuanlan.zhihu.com/p/567832431
socket使用(recv踩坑):https://blog.csdn.net/weixin_43955530/article/details/129947601
Python3 re.search()方法:https://blog.csdn.net/m0_37360684/article/details/84140403
python——正则表达式(re模块)详解:https://blog.csdn.net/guo_qingxia/article/details/113979135
python报错:‘NoneType‘ object has no attribute ‘group‘:https://blog.csdn.net/qfqf123456/article/details/112131627
windows下,在cmd中查看端口占用、进程PID、杀死进程:https://blog.csdn.net/xiongzaiabc/article/details/106600208
附件
行政职业能力测验行测必看:必然性推理直言命题全解析-6种形式、矛盾关系与反对关系解题指南
详解公务员/银行考试行测必然性推理核心模块!掌握直言命题6大标准形式、矛盾关系(所有是↔有些非)、上反对(所有是vs所有非)、下反对(有些是vs有些非)三大关系
Hexo博客EJS主题的相关文章智能推荐插件hexo-article-recommender进阶配置(DIY)
DIY客制化文章底部“文章推荐模块”,本篇文章介绍EJS模板的hexo主题如何实现。hexo-article-recommender为Hexo博客提供本地化智能
Hexo博客NJK主题的相关文章智能推荐插件hexo-article-recommender进阶配置(DIY)
DIY客制化文章底部“文章推荐模块”,本篇文章介绍Nunjucks(NJK)模板的hexo主题(如NexT主题)如何实现。hexo-article-recomm
--- over ---
- 本文链接: https://i-nmb.cn/python-FAQ.html
- 版权声明: 本博客所有文章除特别声明外,均默认采用 CC BY-NC-SA 4.0 许可协议。